
-

路漫漫其修远兮 吾将上下而求索 -
程序员版【成都】——码农最苦逼的内心世界 -
近期评论
-
文章归档
- 2026 年 7 月【 3 篇 】
- 2026 年 6 月【 11 篇 】
- 2026 年 5 月【 2 篇 】
- 2026 年 3 月【 2 篇 】
- 2026 年 2 月【 1 篇 】
- 2025 年 3 月【 1 篇 】
- 2025 年 2 月【 1 篇 】
- 2025 年 1 月【 3 篇 】
- 2024 年 11 月【 1 篇 】
- 2024 年 8 月【 1 篇 】
- 2024 年 7 月【 1 篇 】
- 2024 年 4 月【 4 篇 】
- 2024 年 3 月【 2 篇 】
- 2024 年 2 月【 4 篇 】
- 2023 年 12 月【 1 篇 】
- 2023 年 11 月【 1 篇 】
- 2023 年 10 月【 1 篇 】
- 2023 年 7 月【 1 篇 】
- 2023 年 5 月【 3 篇 】
- 2023 年 4 月【 8 篇 】
- 2023 年 3 月【 1 篇 】
- 2022 年 11 月【 8 篇 】
- 2022 年 10 月【 2 篇 】
- 2022 年 9 月【 2 篇 】
- 2022 年 8 月【 1 篇 】
- 2022 年 7 月【 3 篇 】
- 2022 年 6 月【 6 篇 】
- 2022 年 3 月【 2 篇 】
- 2022 年 2 月【 1 篇 】
- 2021 年 12 月【 2 篇 】
- 2021 年 6 月【 1 篇 】
- 2021 年 5 月【 1 篇 】
- 2021 年 4 月【 1 篇 】
- 2021 年 3 月【 2 篇 】
- 2021 年 1 月【 6 篇 】
- 2020 年 12 月【 2 篇 】
- 2020 年 10 月【 4 篇 】
- 2020 年 9 月【 1 篇 】
- 2020 年 8 月【 3 篇 】
- 2020 年 7 月【 5 篇 】
- 2020 年 4 月【 7 篇 】
- 2020 年 3 月【 6 篇 】
- 2020 年 2 月【 2 篇 】
- 2020 年 1 月【 4 篇 】
- 2019 年 12 月【 6 篇 】
- 2019 年 11 月【 5 篇 】
- 2019 年 10 月【 4 篇 】
- 2019 年 9 月【 3 篇 】
- 2019 年 8 月【 4 篇 】
- 2019 年 7 月【 2 篇 】
- 2019 年 5 月【 2 篇 】
- 2019 年 1 月【 1 篇 】
- 2018 年 12 月【 3 篇 】
- 2018 年 10 月【 3 篇 】
- 2018 年 9 月【 6 篇 】
- 2018 年 8 月【 2 篇 】
- 2018 年 7 月【 9 篇 】
- 2018 年 6 月【 1 篇 】
- 2018 年 5 月【 4 篇 】
- 2018 年 3 月【 1 篇 】
- 2017 年 8 月【 1 篇 】
- 2017 年 3 月【 1 篇 】
- 2017 年 2 月【 2 篇 】
- 2016 年 12 月【 13 篇 】
- 2016 年 11 月【 6 篇 】
- 2016 年 10 月【 5 篇 】
- 2016 年 8 月【 7 篇 】
- 2016 年 7 月【 5 篇 】
- 2016 年 6 月【 7 篇 】
- 2016 年 5 月【 2 篇 】
- 2016 年 4 月【 3 篇 】
- 2016 年 3 月【 1 篇 】
- 2016 年 2 月【 6 篇 】
- 2016 年 1 月【 22 篇 】
- 2015 年 12 月【 6 篇 】
- 2015 年 10 月【 4 篇 】
- 2015 年 9 月【 13 篇 】
- 2015 年 8 月【 31 篇 】
- 2015 年 7 月【 10 篇 】
- 2015 年 6 月【 3 篇 】
- 2015 年 5 月【 14 篇 】
- 2015 年 4 月【 8 篇 】
- 2015 年 3 月【 14 篇 】
- 2015 年 2 月【 17 篇 】
- 2015 年 1 月【 12 篇 】
- 2014 年 12 月【 11 篇 】
- 2014 年 11 月【 9 篇 】
- 2014 年 10 月【 12 篇 】
- 2014 年 9 月【 39 篇 】
- 2014 年 8 月【 28 篇 】
- 2014 年 7 月【 9 篇 】
- 2014 年 6 月【 19 篇 】
- 2014 年 5 月【 14 篇 】
- 2014 年 4 月【 2 篇 】
- 2014 年 3 月【 9 篇 】
- 2014 年 2 月【 2 篇 】
- 2014 年 1 月【 8 篇 】
- 2013 年 12 月【 24 篇 】
- 2013 年 11 月【 39 篇 】
- 2013 年 10 月【 1 篇 】
- 2013 年 8 月【 1 篇 】
- 2013 年 5 月【 3 篇 】
- 2012 年 10 月【 1 篇 】
- 2012 年 4 月【 1 篇 】
- 2011 年 6 月【 2 篇 】
- 2011 年 2 月【 1 篇 】
- 2010 年 10 月【 1 篇 】
- 2010 年 9 月【 1 篇 】
- 2010 年 8 月【 2 篇 】
- 2010 年 6 月【 2 篇 】
- 2010 年 5 月【 1 篇 】
- 2010 年 4 月【 1 篇 】
- 2010 年 3 月【 2 篇 】
- 2010 年 2 月【 1 篇 】
- 2010 年 1 月【 2 篇 】
标签云
AI CentOS Eclipse Error Flex IDE Linux MySQL Spring SpringBoot Ubuntu Win10 Windows Wordpress 下载 书籍 人工智能 励志 国内 国外 大自然 学习笔记 安装 常识 幽默 开发工具 感人 排行 推荐 插件 故事 教程 方法技巧 旅游 日记 框架 爱情 生活 电影 程序员 系统 美景 计算机 软件 配置
-
文章分类
- Android【 7 篇 】
- C/C++【 4 篇 】
- Django【 3 篇 】
- Docker【 2 篇 】
- Eclipse【 7 篇 】
- Elasticsearch【 5 篇 】
- Flex【 12 篇 】
- Flume【 1 篇 】
- Hadoop【 3 篇 】
- Halo【 1 篇 】
- HBase【 1 篇 】
- Hibernate【 2 篇 】
- IdleWolf【 3 篇 】
- IntelliJ IDEA【 8 篇 】
- IT书籍【 11 篇 】
- IT动态【 29 篇 】
- IT实用【 40 篇 】
- IT架构【 5 篇 】
- IT知识【 8 篇 】
- IT经验【 11 篇 】
- IT视频【 2 篇 】
- IT趣闻【 16 篇 】
- Java【 9 篇 】
- Jeecg【 3 篇 】
- Kafka【 3 篇 】
- KVM【 1 篇 】
- Linux【 31 篇 】
- MyBatis【 1 篇 】
- MyEclipse【 6 篇 】
- MySQL【 7 篇 】
- Nacos【 1 篇 】
- Nginx【 3 篇 】
- Oracle【 4 篇 】
- Perl【 1 篇 】
- PHP【 6 篇 】
- Python【 9 篇 】
- Redis【 7 篇 】
- Spring【 1 篇 】
- SpringBoot【 21 篇 】
- SQL【 1 篇 】
- Struts【 4 篇 】
- VirtualBox【 1 篇 】
- VMware【 4 篇 】
- Web【 10 篇 】
- Windows【 6 篇 】
- WordPress【 13 篇 】
- ZooKeeper
- 个人频道【 41 篇 】
- 云计算【 1 篇 】
- 人工智能【 17 篇 】
- 人物频道【 16 篇 】
- 历史频道【 5 篇 】
- 哈哈频道【 16 篇 】
- 外语频道【 4 篇 】
- 大数据【 1 篇 】
- 开发工具【 26 篇 】
- 影视频道【 18 篇 】
- 待发草稿【 1 篇 】
- 思维频道【 2 篇 】
- 情感频道【 40 篇 】
- 房产频道【 5 篇 】
- 探索频道【 16 篇 】
- 操作系统【 1 篇 】
- 数据库【 2 篇 】
- 新闻频道【 4 篇 】
- 旅游频道【 18 篇 】
- 汇编【 1 篇 】
- 汽车频道【 3 篇 】
- 游戏频道【 4 篇 】
- 理财频道【 4 篇 】
- 生活频道【 16 篇 】
- 蛋蛋故事【 6 篇 】
- 错误警告【 12 篇 】
- 阅读频道【 24 篇 】
- 音乐频道【 3 篇 】
已阻挡的垃圾评论
其他操作
分类目录归档:ZooKeeper

原计划在介绍完ZK Client之后就着手ZK Server的介绍,但是发现ZK Server所包含的内容实在太多,并不是简简单单一篇Blog就能搞定的。于是决定从基础搞起比较好。 那么ZK Server最基础的东西是什 … 继续阅读
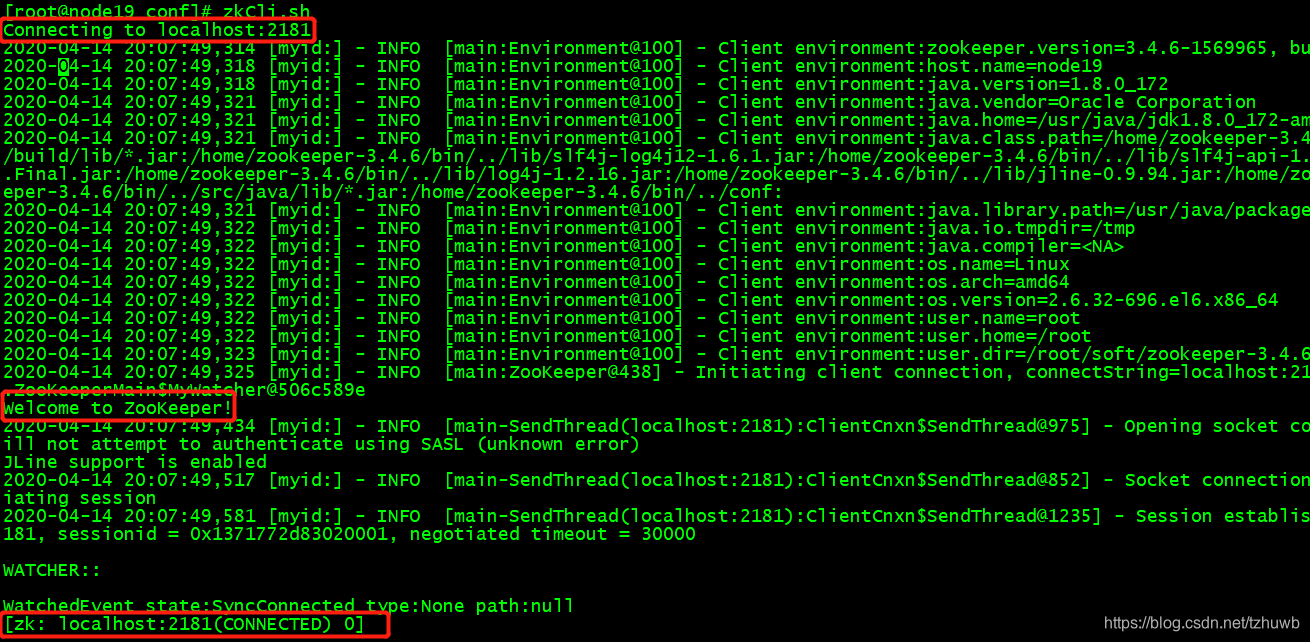
从前面一系列的基础部署教程中,可以看到大数据集群的部署中,为了保证集群的高可用性,一般都会配置 Zookeeper,比如 Kafka 集群的搭建中,就添加了 Zookeeper 配置。所以这篇补充一下 Zookeeper … 继续阅读