
在以前一篇《大数据学习初级入门教程(一) —— Hadoop 2.x 完全分布式集群的安装、启动和测试》中,详细写了 Hadoop 完全分布式集群的安装步骤,在上一篇《大数据学习初级入门教程(十一) —— Zookeeper 3.4.6 完全分布式集群的安装、配置、启动和测试》中详细写了 Zookeeper 完全分布式集群的安装步骤,所以这篇写一下如何让两个集群做集成,让 Zookeeper 保证 Hadoop 集群的高可用。
一、环境准备
上面两篇文章中已经详细叙述,这里略过。
规划节点:node19(namenode),node18(namenode),node11(datanode),node12(datanode),node13(datanode),特别注意:两台及以上的 namenode 要互相免密码登陆。
二、删掉文件
删掉原 Hadoop 集群中各个节点中配置的 masters 文件:
# rm -rf /home/hadoop-2.5.1/etc/hadoop/masters
删掉 hadoop 集群启动生成的文件:
# rm -rf /opt/hadoop
注意:上面删除文件操作在所有 Hadoop 节点执行。
三、修改配置文件
修改 hdfs-site.xml 配置文件,内容如下:
- <?xml version=”1.0” encoding=”UTF-8“?>
- <?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
- <!–
- Licensed under the Apache License, Version 2.0 (the “License”);
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
- http://www.apache.org/licenses/LICENSE-2.0
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an “AS IS” BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License. See accompanying LICENSE file.
- –>
- <!– Put site-specific property overrides in this file. –>
- <configuration>
- <property>
- <name>dfs.nameservices</name>
- <value>mllcluster</value>
- </property>
- <property>
- <name>dfs.ha.namenodes.mllcluster</name>
- <value>nn19,nn18</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.mllcluster.nn19</name>
- <value>node19:8020</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.mllcluster.nn18</name>
- <value>node18:8020</value>
- </property>
- <property>
- <name>dfs.namenode.http-address.mllcluster.nn19</name>
- <value>node19:50070</value>
- </property>
- <property>
- <name>dfs.namenode.http-address.mllcluster.nn18</name>
- <value>node18:50070</value>
- </property>
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://node11:8485;node12:8485;node13:8485/mllcluster</value>
- </property>
- <property>
- <name>dfs.client.failover.proxy.provider.mllcluster</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>sshfence</value>
- </property>
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>/root/.ssh/id_dsa</value>
- </property>
- <property>
- <name>dfs.journalnode.edits.dir</name>
- <value>/opt/journalnode/data</value>
- </property>
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
- <!–
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>node18:50090</value>
- </property>
- <property>
- <name>dfs.namenode.secondary.https-address</name>
- <value>node18:50091</value>
- </property>
- –>
修改 core-site.xml 配置文件,内容如下:
- <?xml version=”1.0” encoding=”UTF-8“?>
- <?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
- <!–
- Licensed under the Apache License, Version 2.0 (the “License”);
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
- http://www.apache.org/licenses/LICENSE-2.0
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an “AS IS” BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License. See accompanying LICENSE file.
- –>
- <!– Put site-specific property overrides in this file. –>
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://mllcluster</value>
- <!– <value>hdfs://node19:9000</value>–>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/hadoop/hadoop-2.5</value>
- </property>
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>node19:2181,node18:2181,node11:2181</value>
- </property>
- </configuration>
从上面配置可以看到配置了 Zookeeper 集群。
四、配置其它节点
拷贝配置文件到其它机器,使得各个节点的配置保持一致。
scp -r ./* root@node18:/home/hadoop-2.5.1/etc/hadoop/
scp -r ./* root@node11:/home/hadoop-2.5.1/etc/hadoop/
scp -r ./* root@node12:/home/hadoop-2.5.1/etc/hadoop/
scp -r ./* root@node13:/home/hadoop-2.5.1/etc/hadoop/
五、启动 JournalNode 节点
通过第三步,可以看到 JournalNode 节点配置在 node11、node12 和 node 13,通过下面命令启动 JournalNode 节点,
# hadoop-daemon.sh start journalnode
备注:
JournalNode 也是一个小集群,用来对 hadoop 集群的 edits、fsimage 文件进行合并操作。
停止命令是:hadoop-daemon.sh stop journalnode
检查是否启动成功,命令如下:
# more /home/hadoop-2.5.1/logs/hadoop-root-journalnode-node13.log
无错误日志输出则表示启动成功。
六、格式化 Hadoop 集群
在一台 NameNode 节点上执行命令,这里在 node18 节点上执行下面命令:
# hdfs namenode -format
执行后把格式化生成的文件,全部同步到另外一台 NameNode 节点:
# scp -r root@node18:/opt/hadoop /opt/
七、初始化 HA 配置
在其中一台 namenode 上,初始化高可用(HA)配置数据,命令如下:
# hdfs zkfc -formatZK
八、启动 Hadoop 集群
# start-dfs.sh
启动集群信息如下:
Starting namenodes on [node18 node19]
node18: starting namenode, logging to /home/hadoop-2.5.1/logs/hadoop-root-namenode-node18.out
node19: starting namenode, logging to /home/hadoop-2.5.1/logs/hadoop-root-namenode-node19.out
node12: starting datanode, logging to /home/hadoop-2.5.1/logs/hadoop-root-datanode-node12.out
node13: starting datanode, logging to /home/hadoop-2.5.1/logs/hadoop-root-datanode-node13.out
node11: starting datanode, logging to /home/hadoop-2.5.1/logs/hadoop-root-datanode-node11.out
Starting journal nodes [node11 node12 node13]
node13: journalnode running as process 1915. Stop it first.
node11: journalnode running as process 2324. Stop it first.
node12: journalnode running as process 2010. Stop it first.
Starting ZK Failover Controllers on NN hosts [node18 node19]
node18: starting zkfc, logging to /home/hadoop-2.5.1/logs/hadoop-root-zkfc-node18.out
node19: starting zkfc, logging to /home/hadoop-2.5.1/logs/hadoop-root-zkfc-node19.out
由于 journalnode 节点在第五步已经启动,可以看到日志提示已经运行中。
九、测试集群是否正常
除了通过查看集群日志有无报错来判断集群是否启动正常外,也可以通过 jps 命令查看集群进程信息:
[root@node19 hadoop]# jps
6417 DFSZKFailoverController
6129 NameNode
5298 QuorumPeerMain
6495 Jps[root@node18 ~]# jps
3521 NameNode
3617 DFSZKFailoverController
1465 QuorumPeerMain
3695 Jps[root@node11 ~]# jps
2337 JournalNode
2247 DataNode
1485 QuorumPeerMain
2398 Jps[root@node12 ~]# jps
2210 DataNode
2296 JournalNode
1468 QuorumPeerMain
2351 Jps[root@node13 ~]# jps
2293 JournalNode
2350 Jps
2207 DataNode
1455 QuorumPeerMain
还有一种方式可以测试集群是否正常启动,就是可以直接通过浏览器访问监控页面 http://192.168.220.19:50070/ 和 http://192.168.220.18:50070/,可以分别看到如下页面信息:
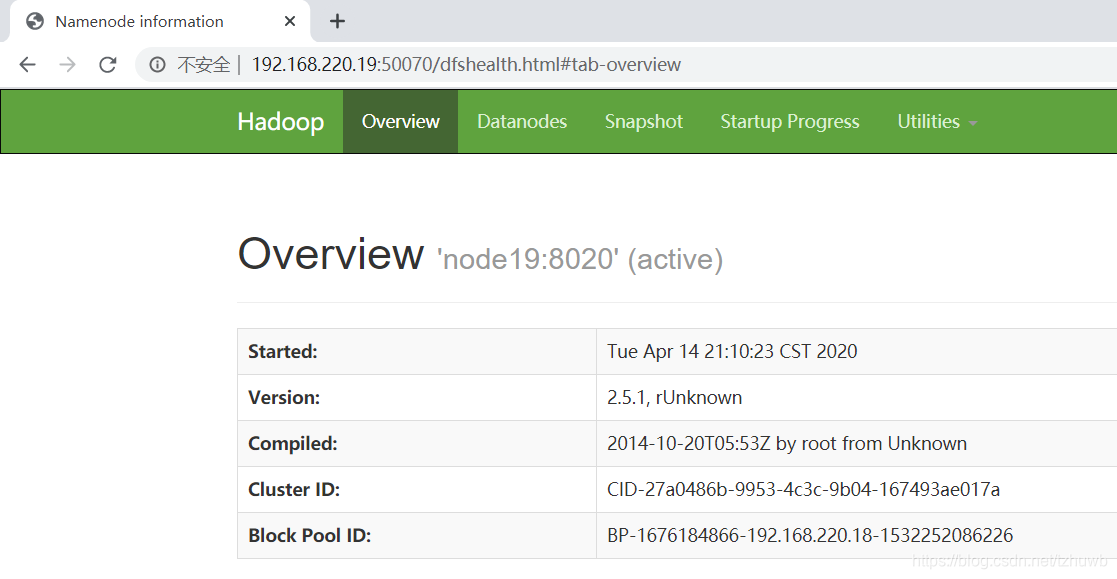
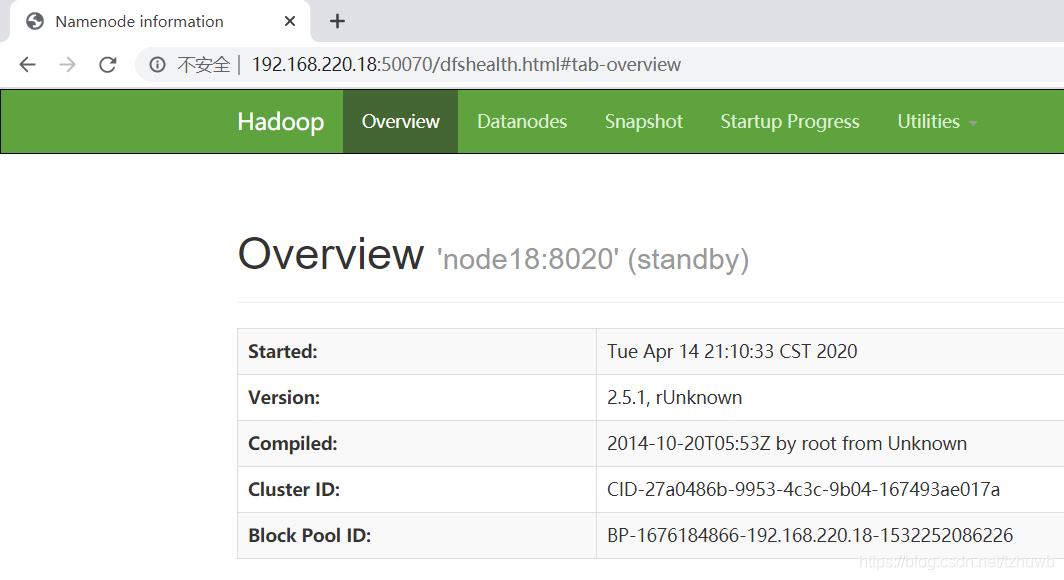
十、测试高可用
测试两个 NameNode 是不是可以高可用,可以 kill 掉 active 的 NameNode 节点,这里是 node19,另一个 standby 节点就会变为 active。
通过 jps 可以看到 node19 上的 NameNode 节点进程信息为:
6129 NameNode
# kill -9 6129
再次访问监控页面,可以看到 node18 已变为 active 状态:
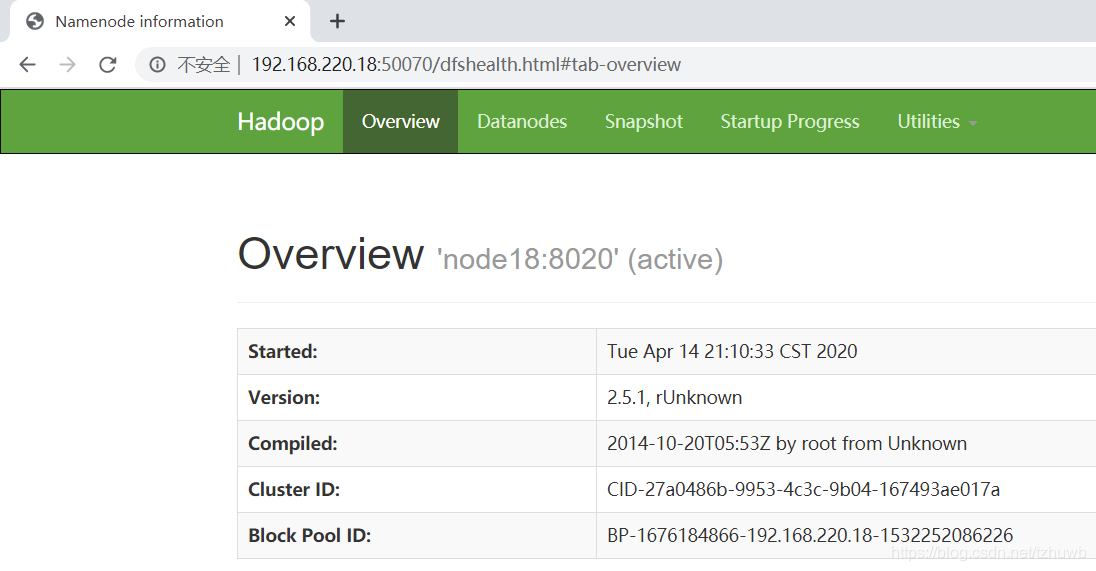
十一、其它一些命令
启动 kill 掉的 namenode 节点:hadoop-daemon.sh start namenode
手动切换 active 节点:hdfs haadmin -transitionToActive nn19
注意:自动切换开启后该命令不成功,需关闭自动切换才能好用。
创建目录:hdfs dfs -mkdir /test
十二、停止 Hadoop 集群
# stop-dfs.sh
停止集群信息如下:
Stopping namenodes on [node18 node19]
node18: stopping namenode
node19: stopping namenode
node11: stopping datanode
node12: stopping datanode
node13: stopping datanode
Stopping journal nodes [node11 node12 node13]
node11: stopping journalnode
node13: stopping journalnode
node12: stopping journalnode
Stopping ZK Failover Controllers on NN hosts [node18 node19]
node18: stopping zkfc
node19: stopping zkfc
到此,Hadoop 集群和 Zookeeper 集群的集成基本完成。







《大数据学习初级入门教程(十二) —— Hadoop 2.x 集群和 Zookeeper 3.x 集群做集成》有0条回应