
好久没用 Hadoop 集群了,参考以前写的《大数据学习初级入门教程(一) —— Hadoop 2.x 完全分布式集群的安装、启动和测试》和《大数据学习初级入门教程(十二) —— Hadoop 2.x 集群和 Zookeeper 3.x 集群做集成》,下载了目前官网最新的版本 hadoop-3.3.5 再重温下集群部署。按步骤进行到格式化集群步骤时,发现不少和老版本不一致的地方,这里记录如下。
问题1)ERROR: Attempting to operate on *** as root
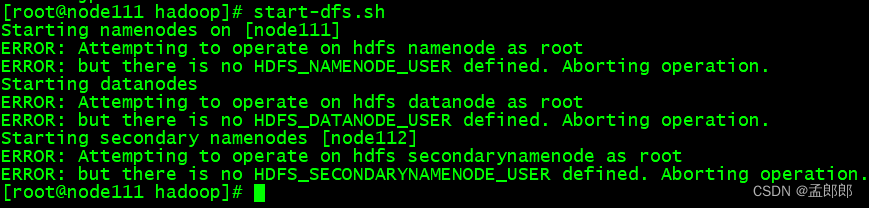
[root@node111 hadoop]# start-dfs.sh
Starting namenodes on [node111]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [node112]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.Starting journal nodes [node115 node114 node113]
ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation.
Starting ZK Failover Controllers on NN hosts [node111 node112]
ERROR: Attempting to operate on hdfs zkfc as root
ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.
[root@node111 hadoop]#
查了下资料,解决方法是在环境变量配置中加上下面这些配置:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
注意:添加完后,一定执行命令 source ~/.bash_profile 让配置立刻生效。
还有一种方式如下,稍微繁琐些,请自行尝试。
1)将start-dfs.sh,stop-dfs.sh(在hadoop安装目录的sbin里)两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2)将start-yarn.sh,stop-yarn.sh(在hadoop安装目录的sbin里)两个文件顶部添加以下参数YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
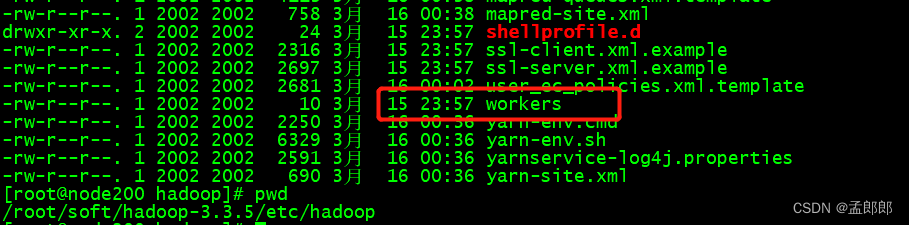
问题2)启动集群时,发现 Namenode 节点总是启动了 Datanode
每次启动集群后,Namenode节点总是启动了 Datanode,最后发现新的版本中配置 Datanode文件为 /etc/hadoop/workers,不需要和原来那样创建 /etc/hadoop/slaves 了。
问题3)启动 journalnode 节点命令
新版本启动 journalnode 节点的命令变更如下,原命令已废弃。
hdfs –daemon start journalnode
more /soft/hadoop/hadoop-3.3.5/logs/hadoop-root-journalnode-node115.log
hdfs –daemon stop journalnode
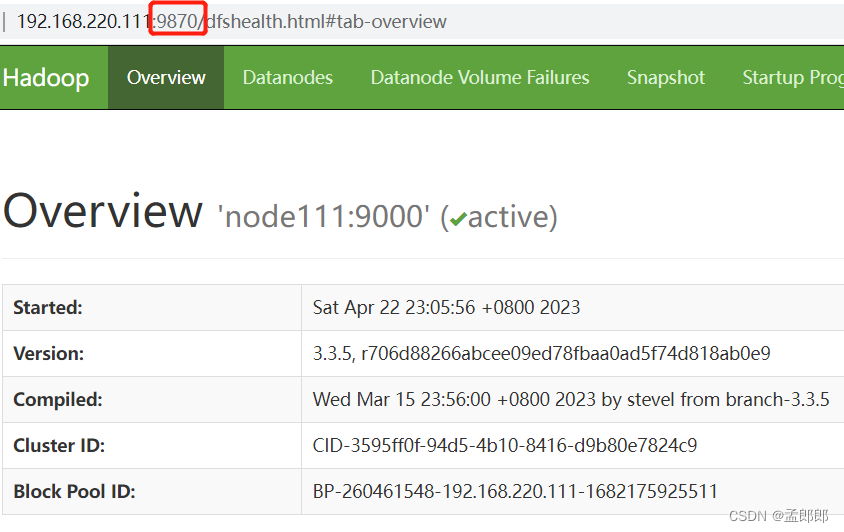
问题4)如果访问路径 http://192.168.220.19:50070/ 无法打开页面
启动后浏览器访问 namenode 节点的监控页面,访问路径为:http://192.168.220.19:50070/,结果页面打不开,看官网发现新版本把 namenode 端口变了,访问 9870 端口即可。
问题5)测试集群高可用时,standby 无法切换为 active 状态
查看 standby 所在节点的日志,可以发现 Connection refused 错误,详细如下:
PATH=$PATH:/sbin:/usr/sbin fuser -v -k -n tcp 8020 via ssh: bash
: fuser: command not found
这是因为在 hdfs-site.xml 中配置了如下配置:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
因为机器上没有 fuser 程序,导致无法进行 fence,安装 psmisc 即可解决问题。
yum install psmisc
以上是部署新版集群踩的一些坑,顺手记录一下。
Good Luck!






《大数据学习初级入门教程(十六) —— Hadoop 3.x 完全分布式集群的安装、启动和测试》有0条回应