
大数据最基础的就是数据的存储和计算,而 Hadoop 就是为存储和计算而生,是最基础的大数据处理工具。这篇简单写写 Hadoop 2.x 的安装,启动和测试。
一、准备环境
大数据环境的部署,一般都是集群,机器数量为奇数,这里以 5 台机器为例,操作系统为 CentOS 6.9_x64;IP 分别为 192.1688.220.19,192.1688.220.18,192.1688.220.11,192.1688.220.12,192.1688.220.13;Hadoop 的安装包版本为 hadoop-2.5.1_x64.tar.gz。
机器准备好之后,需要做下面几件事:
1)让各台机器间网络互通;
2)让各台机器的时间保持一致或接近,保证各个机器的时间同步,30s 以内就行,不一定一模一样;
3)让各台机器间 SSH 互通;
4)让各台机器都安装了 Java 环境;
5)修改各台机器的主机名,分别为 node19,node18,node11,node12,node13;
6)规划节点:node19(namenode),node18(second namenode),node11(datanode),node12(datanode),node13(datanode)。
二、上传解压安装包
为了简单期间,包直接放在 node19 机器的 /home 目录下,上传后解压包即可。
三、配置 Java 环境变量
修改 /home/hadoop-2.5.1/etc/hadoop/hadoop-env.sh 中的 JAVA_HOME。
把:
export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/usr/java/jdk1.7.0_79四、配置接口及端口
配置主机名和数据传输的接口及端口,fsimage 存放路径,修改 /home/hadoop-2.5.1/etc/hadoop/core-site.xml。
把:
<configuration>
</configuration>
修改为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node19:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.5</value>
</property>
</configuration>五、配置 Sencondary 的协议地址和端口
配置 namendoe 的 sencondary 的协议地址和端口,修改 /home/hadoop-2.5.1/etc/hadoop/hdfs-site.xml。
把:
<configuration>
</configuration>
修改为:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node18:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node18:50091</value>
</property>
</configuration>六、配置 datanode 的主机
修改 /home/hadoop-2.5.1/etc/hadoop/slaves。
node11
node12
node13七、配置 second namenode 主机
修改 /home/hadoop-2.5.1/etc/hadoop/masters,如果没有该文件可以自己创建。
node18八、拷贝安装包到其它机器
拷贝上面配置好的 hadoop 目录到其它机器上。
scp -r hadoop-2.5.1/ root@node18:/home/
scp -r hadoop-2.5.1/ root@node11:/home/
scp -r hadoop-2.5.1/ root@node12:/home/
scp -r hadoop-2.5.1/ root@node13:/home/九、检查 hosts 配置
保证两台 namenode、三台 datanode 的 hosts 文件一致。
192.168.220.11 node11
192.168.220.12 node12
192.168.220.13 node13
192.168.220.18 node18
192.168.220.19 node19十、配置 hadoop 环境变量
export HADOOP_HOME=/home/hadoop-2.5.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin到此,配置基本搞定,可以开始启动集群工作。
十一、格式化集群
在 namenode 节点上执行格式化命令
hdfs namenode -format
作用是:/opt/hadoop/hadoop-2.5/dfs/name/current 下创建了 fsimage 文件。
十二、启动集群
start-dfs.sh
log日志如下:
Starting namenodes on [node19]
node19: starting namenode, logging to /home/hadoop-2.5.1/logs/hadoop-root-namenode-node19.out
node13: starting datanode, logging to /home/hadoop-2.5.1/logs/hadoop-root-datanode-node13.out
node11: starting datanode, logging to /home/hadoop-2.5.1/logs/hadoop-root-datanode-node11.out
node12: starting datanode, logging to /home/hadoop-2.5.1/logs/hadoop-root-datanode-node12.out
Starting secondary namenodes [node18]
node18: starting secondarynamenode, logging to /home/hadoop-2.5.1/logs/hadoop-root-secondarynamenode-node18.out十三、测试是否启动成功
浏览器访问 namenode 节点的监控页面,访问路径为:http://192.168.220.19:50070/,如果出现如下页面,说明集群启动成功。
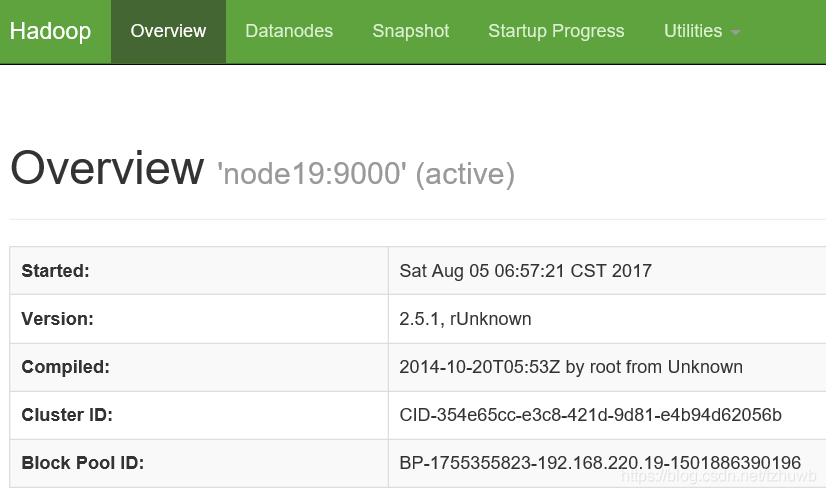
同理,可以访问 namenode secondary 监控页面:http://192.168.220.18:50090/。
十四、停止集群
stop-dfs.sh
日志如下:
Stopping namenodes on [node19]
node19: stopping namenode
node12: no datanode to stop
node13: no datanode to stop
node11: no datanode to stop
Stopping secondary namenodes [node18]
node18: stopping secondarynamenode基础的安装和配置到此结束~






《大数据学习初级入门教程(一) —— Hadoop 2.x 完全分布式集群的安装、启动和测试》有0条回应